流是什么?
流是个抽象的概念,是对输入/输出设备(文件,网络,内存等)的抽象,在java程序中,对于数据的输入/输出操作都是以“流”的方式进行。
流的分类
1、通过方向区分:输入流、输出流
以程序为参考,如果数据的流向是程序至设备,称为输出流,反之称为输入流。
2、通过处理单位区分:字节流、字符流
在程序中,处理流的最小单位为字节(byte)则称为字节流,最小单位为字符(char)则称为字符流。
在java中,我们对文件的操作一般使用字节流进行,因为文件就是一堆二进制数据(字节)的集合。但是在实际的使用中,大部分处理的文件都是文本文件,也就是字符串类型,为了方便java也提供了字符流的操作方法来操作文本文件。总的来说其实两种方法没有太大的区别,在代码中的使用也都差不多。在代码中区分这两种流的操作也很简单:使用的操作类以stream结尾的就是字节流,reader或writer结尾的就是字符流。
我这里准备了一个文本文件:静夜思.txt 用来对两种办法读取文件进行演示。
静夜思
李白 唐
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
我分别使用字节流(InputStream)和字符流(Reader)两种形式读取文件并返回一个字符串,演示使用,我对文件相关的异常仅直接捕获并抛出运行时异常。
public class Test {
public static void main(String[] args) {
String path = "/Users/liqingcan/Desktop/静夜思.txt";
System.out.println(readString(path));
System.out.println(readStringByReader(path));
}
/**
* 通过字节流的形式读取文件
* @param path
* @return
*/
public static String readString(String path) {
StringBuilder sb = new StringBuilder();
File file = new File(path);
try {
InputStream is = new FileInputStream(file);
byte[] buffer = new byte[1024];
int len;
while ((len=is.read(buffer)) != -1) {
sb.append(new String(buffer,0,len));
}
is.close();
} catch (IOException e) {
throw new RuntimeException("读取异常:"+e.getMessage());
}
return sb.toString();
}
/**
* 通过字符流的形式读取文件
* @param path
* @return
*/
public static String readStringByReader(String path) {
StringBuilder sb = new StringBuilder();
File file = new File(path);
try {
Reader reader = new FileReader(file);
char[] buffer = new char[1024];
int len;
while ((len=reader.read(buffer)) != -1) {
sb.append(new String(buffer,0,len));
}
reader.close();
} catch (IOException e) {
throw new RuntimeException("读取异常:"+e.getMessage());
}
return sb.toString();
}
}
可以看到,两种办法读取文件的代码结构基本类似。字节流读取中,新建一个FileInputStream,调用这个类的read(buffer)方法。代码会将读取到的字节数据放到我们预先定义的字节数组buffer中,并且返回读取到的数据长度,如果文件已经读取完了则返回-1。因为文件的大小不可能是固定的,所以我们预先定义的数组长度为1024,并且循环读取数据,读取一次就将buffer字节数组中的数据转成一个字符串添加到StringBuilder中,知道文件数据完全读取完毕。而字符流的读取中,区别就在于FileInputStream替换成了FileReader,buffer字节数组替换成了字符串数组,其他的完全类似。
这里有几个需要注意的地方:
1、在我们将buffer数组转换成字符串时,一定要使用new String(buffer,0,len)这样带len参数的形式,否则会出现下面这种情况: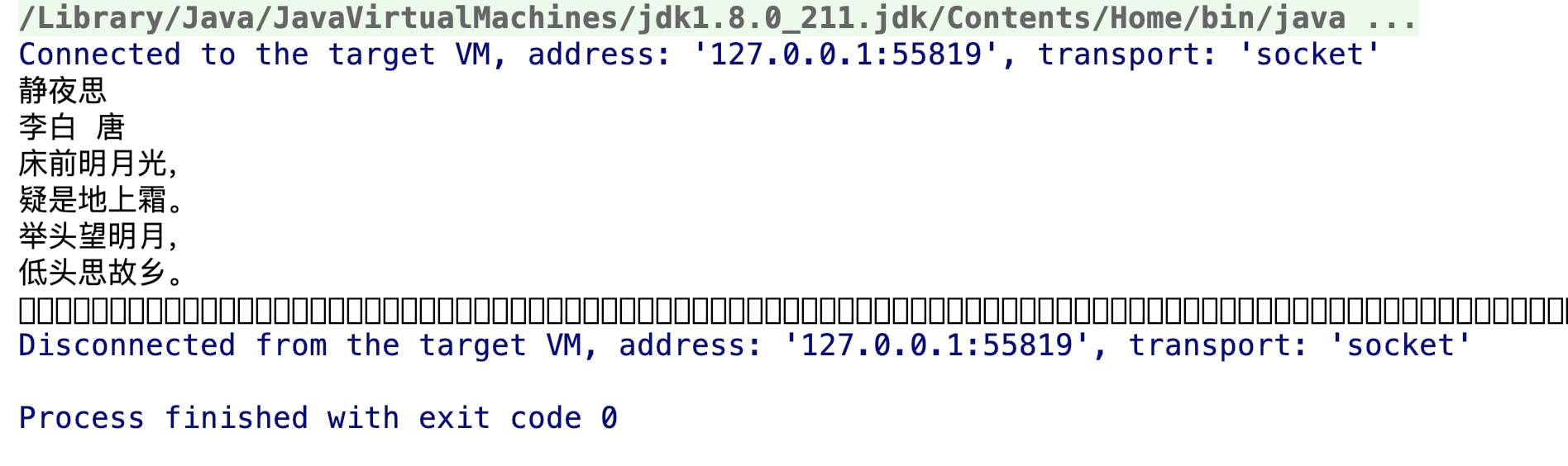
你会发现结尾有一堆的空格方框,原因是什么呢?因为我们定义的buffer数组长度为1024,但是文件最后一次读取流到buffer数组时,因为文件长度的问题,可能只占用了buffer数组的一部分,即buffer数组中存在脏数据,如果我们在new String(buffer,0,len)的时候没有带len参数而是直接使用new String(buffer),则是将整个buffer数组转换成字符串,这样我们的字符串就是有问题的字符串了。
2、无论是使用InputStream还是Reader,在操作结束之后一定要记得调用close方法。
不调用close方法在短期内执行程序其实也是没有问题的,但是因为没有调用close方法,程序对文件资源的占用就不会释放,在长时间的执行之后,要么就是会发生内存不够溢出,要么就是会触发了操作系统的异常,如:
3、我们到底要使用字节流还是字符流来操作文件呢?
如果你操作的是非文本类型的文件,如:图片,视频等,那么答案是绝对的:字节流。
如果你操作的是文本类型的文件,如:txt文本,日志文件等,那么答案是:看你心情,两种都可以。


